TCP延申
文章目录
粘包问题
粘包问题中的”包“,指的是应用层的数据包
TCP是基于字节流的,只维护发送出去多少,确认了多少,并不会维护消息和消息的边界,这就导致了粘包问题,他在应用层取数据的时候,不知道从哪里到哪里是一个完整的应用层数据包,面向字节流读文件都会有这种问题
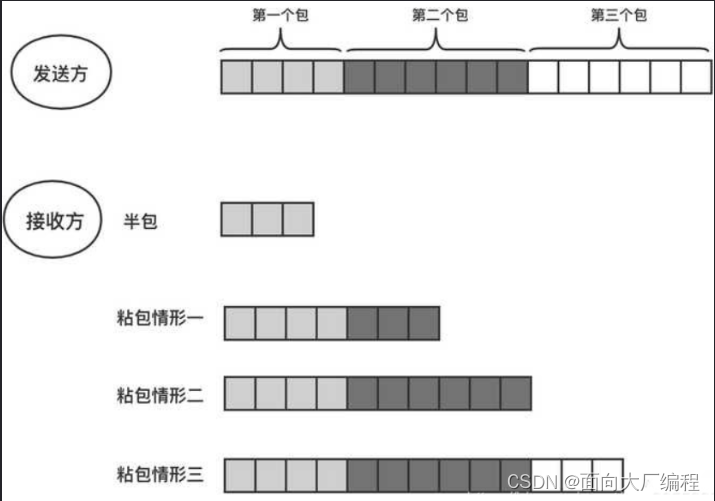
数据就变得混乱了
怎么解决呢?
由于找不到应用层的数据始末,所以去TCP 上面做功夫肯定是不行的,所以解决这个问题就是要在应用层协议中加上包和包之间边界,比如在应用层数据报的结尾加上一个**;**这样在读取的时候,就能区分出一个完整的应用层数据报了,
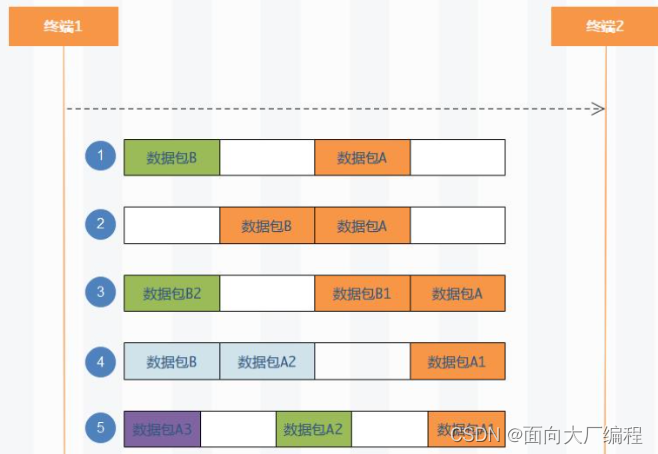

读取http请求的
1 | |
- 定长发送,缓冲区大小都是1024
- 特殊字符,遇到这个字符就分离
- 自描述,自己进行定制协议
TCP 异常处理
TCP协议传输时会出现以下几种情况
连接崩溃的情况
- 机器关机/重启:会释放文件描述符,发送
FIN,和正常关闭一样,和进程终止是一样的 - 进程终止:和机器重启一样,底层会自动4次挥手,文件描述符自动关
在进程毫无准备的情况下,突然结束进程,
我们知道TCP 连接是通过socket进行的,socket本质就是打开了一个文件,文件就存在于PCB的文件描述符表之中,每次打开一个socket文件都会在文件描述符表添加一项,删除会减少的一项
当强制结束进程时,PCB没了,里面的文件描述符表也没了,就相当于自动关闭了,也依然会执行四次挥手的过程
网线断开/机器断电:断电时没有时间给操作系统去反应,来不及四次挥手,如果客户端断电,客户端不会给服务器发送任何数据,服务器会尝试重新连接,重连一定次数的话,就会放弃连接,接收端的连接还在,当接收端对我进行写入,会收到一个
reset然后TCP 内不设置一个保活定时器(比较鸡肋),询问对方是否还在,不在就释放连接但是最好不要把保活定时器作为一个应用层的工具,因为不同的应用层对于连接是否需要关闭是不一样的,比如QQ,在断线之后,也会定期尝试重新连接
用UDP实现可靠传输
- 引入序列号:保证数据的顺序型
- 引入确认应答机制:对端收到的数据都要进行应答
- 超时重传:数据隔一段时间没收到进行重新传
- 校验和:使用校验和,避免发送错误
- 流量控制:对发送的数据进行管理
TCP 太重了,udp比较轻量化
TCP相关实验
理解Listen的第二个参数
listen第二个参数+1=在TCP层建立正常连接的个数,不是只能在服务器段维护几个连接
1 | |

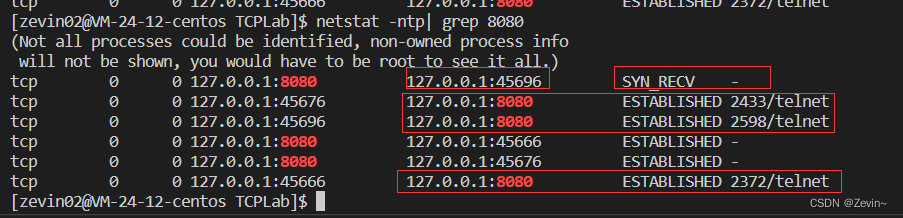
Linux内核协议栈为一个TCP连接管理使用两个队列
半连接队列(用来保存处于SYN_RECV和SYN_SEND状态的请求),握手之中全连接队列(acceptd队列)(用来保存处于established状态,但是应用层没有调用accept取走的请求,暂时没有被读取),握手成功
全连接队列长度会受listen第二个参数影响(n+1):长度至少为1
为什么要维护队列(全链接)?为什么这个队列不能过长?为什么这个队列不能没有?
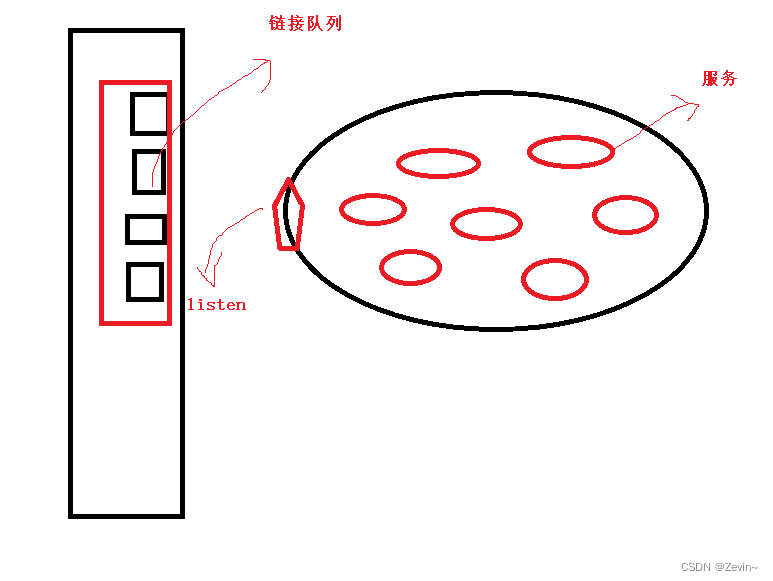
- 上层的服务太忙了, 服务打满了,来不及去接收新的服务,只能让它在队列里面(避免内部资源没有被充分利用)
- 当内部满的时候,一旦有人退出,就可以立马把队列里面的取走,保证内部资源被100%利用
- 如果把队列弄太长了,维护队列也是有成本的,成本太高了,长时间链接没有反应,客户就会把服务关掉,把省出来的,让服务去使用,让服务以较高的效率提供服务
- listen就相等于在门口叫号的